Train a Multi-Object Tracker
In this tutorial, we will train a model to perform multi-object tracking (MOT), where we find the tracks of all objects of a certain type. An object track is the sequence of positions where an object appears in a video.
We'll be using the unsupervised MOT technique from Self-Supervised Learning for Multi-Object Tracking, which does not require any video-level training data. This means that all we need to train a multi-object tracker is an accurate object detection model.
To get started, you'll need:
- A dataset containing videos.
- An object detection model that works well at detecting the type of object that you're interested in.
If you don't have your own data, you can use our example dataset, which detects cars in traffic camera video captured in Tokyo:
- Video dataset: https://skyhookml.org/datasets/tokyo-videos.zip
- Object detection model: https://skyhookml.org/datasets/tokyo-detector.zip (Alternatively, if you followed Train an Object Detector with our example data, you can reuse that model.)
Before diving in, here's a high-level overview of the steps in this tutorial.
- Compute object detections in the video dataset. This provides automatically computed bounding boxes that the unsupervised tracking technique requires.
- Train a re-identification model through self-supervised learning. This model predicts whether two bounding boxes in different frames contain the same object.
- Apply the model and visualize its outputs.
Compute Object Detections
The unsupervised tracking technique requires a large amount of unlabeled video with automatically computed bounding boxes. So, the first step is to apply an object detector to compute bounding boxes.
Go to Dashboard, press Apply a Model, and select Object Detection. Choose the model architecture that was used for training the detection model (YOLOv5l if using the example), and select the video dataset as the input.
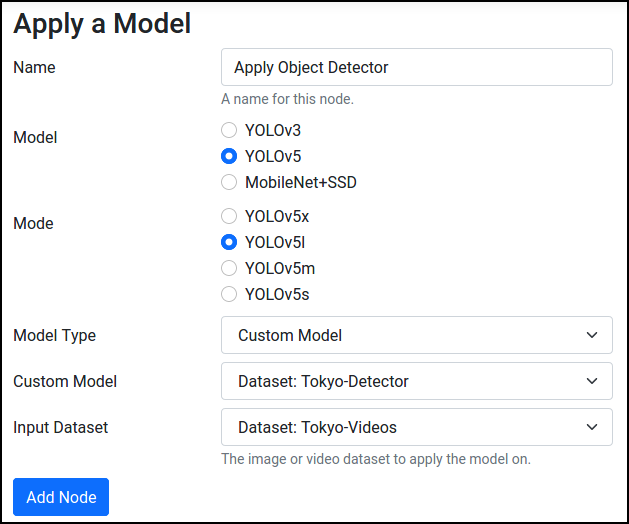
For the Tokyo dataset, if using our example detector, use these parameters in the inference node, where we input the video at 960x544:
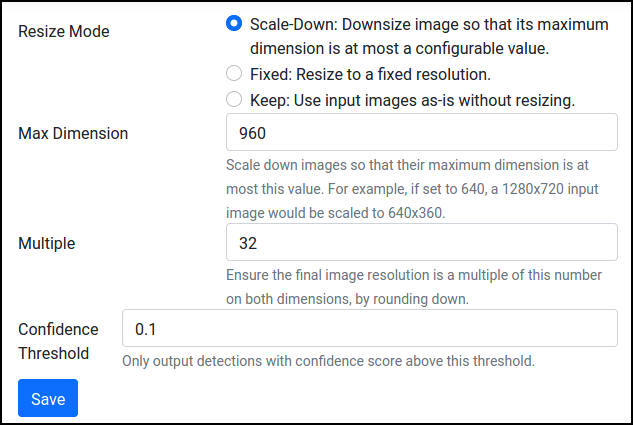
Then, from Pipeline, select the node and press Run. This process may take a while since it involves applying the detector on six hours of video captured at 10 fps.
Train Re-identification Model
We can now train a re-identification model. The technique we use here utilizes self-supervised learning to avoid the need for any object track labels, i.e., we can use the bounding boxes computed in video in the previous step without needing to label boxes with track IDs.
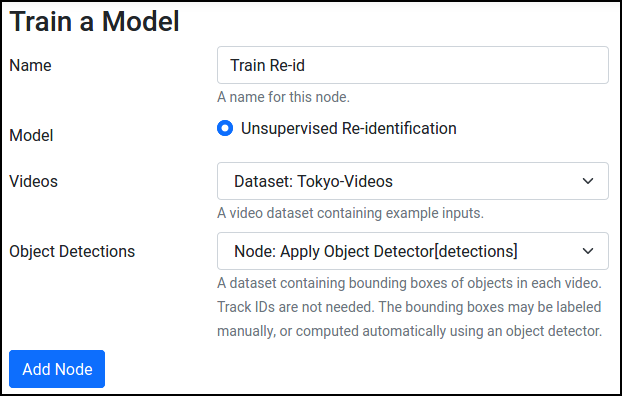
- Go to Dashboard, press Train a Model, and select Object Tracking.
- Select Unsupervised Re-identification, and choose the video dataset and the object detector inference node.
- After creating the node, press Save.
- Finally, select the node from Pipeline and press Run to begin training.
Apply the Tracker
Finally, we can use the learned re-identification model to track objects in video.
Go to Dashboard, press Apply a Model, and select Object Tracking. Select Unsupervised Re-identification, and choose the model and the video dataset:
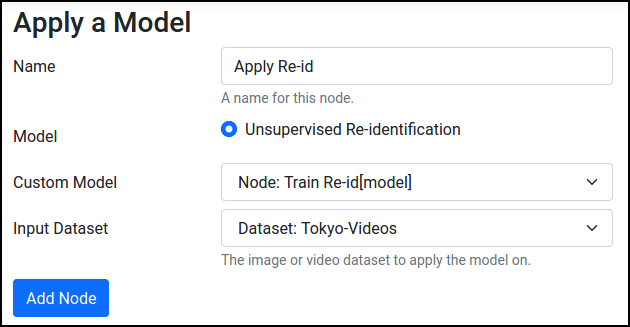
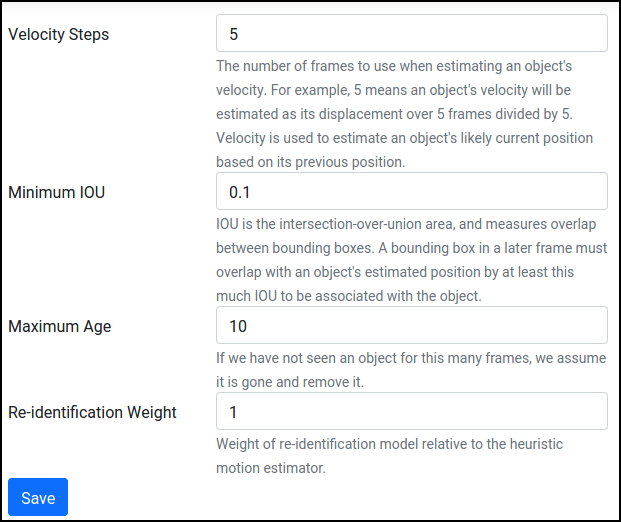
The default parameters work fine for the example dataset, but you can read what they do and tweak them if desired:
You will need to manually set the "detections" input to the tracker operation in the pipeline: the Re-identification Tracker operation expects to input not only the video data, but also bounding boxes computed by the object detector.
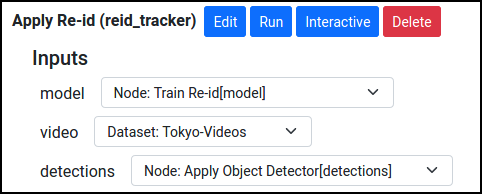
Now, you should be able to select the node and run it.
After it completes, you can add a Render Images or Video node to visualize the outputs: press Add Node, select Render Images or Video under Images and Video, and add both the video data and computed tracks as inputs:
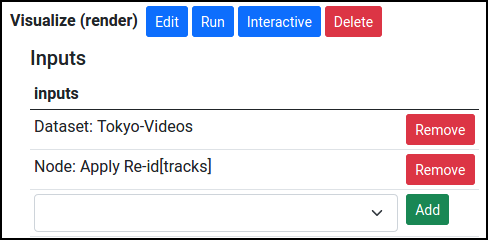
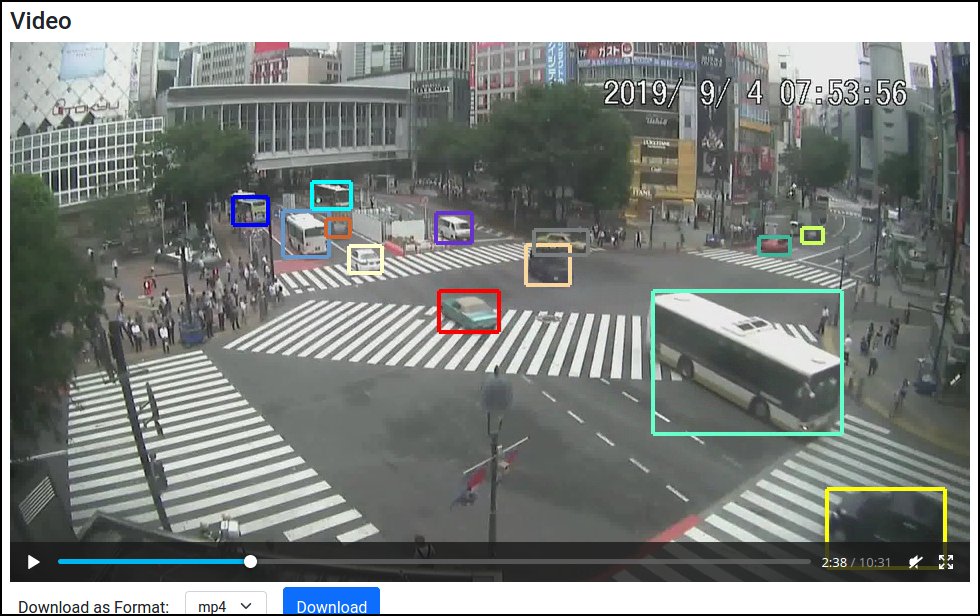
After running the render node, you'll be able to see the output videos from Datasets, where different cars are shown with different colors: