Python Nodes
Python nodes in Skyhook enable somewhat easily injecting custom code into computer vision pipelines. Python operations can be customized to input one or more datasets, and output one or more arbitrary data types. To add a Python node:
- Go to Pipeline, and press Add Node.
- For the operation, select Python under the Code category.
Once added to the pipeline, the first step is generally to define the inputs and output types of the operation. For example, suppose we want to define a custom operation that inputs images and segmentation outputs (Array type) and outputs images that visualize the segmentation results. First, we can set the inputs by selecting the operation:
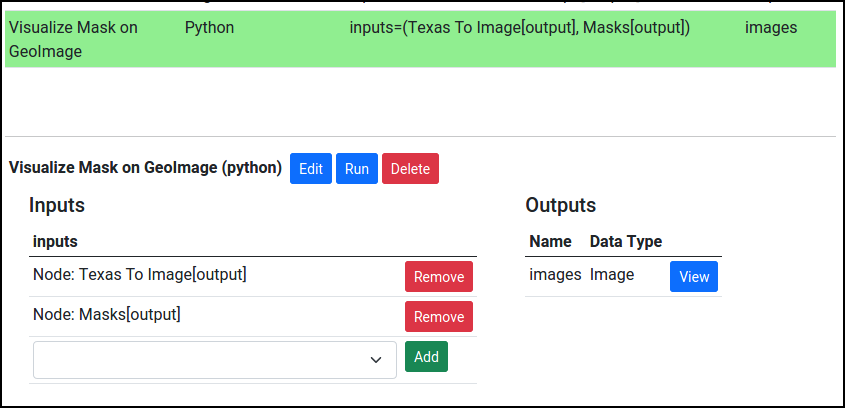
Then, after pressing Edit, we can also set the outputs:
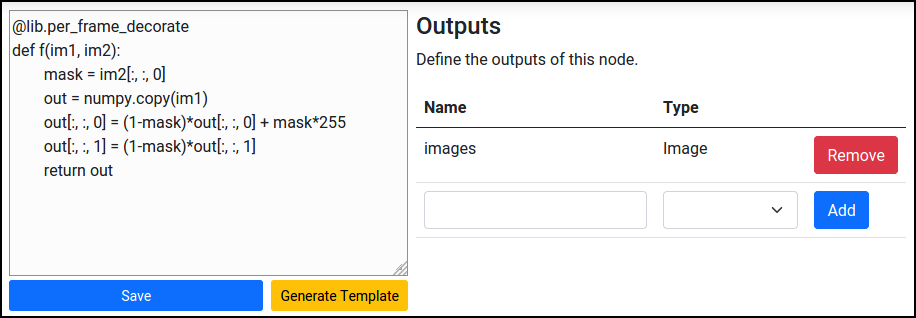
Also, you can press Generate Template to generate boilerplate code based on the currently configured inputs and outputs of the Python operation.
Code Specification
Creating a Python operation primarily involves developing a piece of Python code that the operation executes. This code should define a function "f" with a particular function signature (which can be generated with Generate Template). You can define other functions or import packages as well.
Generally, you will use one of two decorators to implement the function:
@per_frame: the function is called on each element of a sequence data type. For example, each image in a video, or a list of detections computed in each frame of video.@all_decorate: the function is called on the entire data. For example, all object detections computed over an entire video, or tabular data.
Below we show several example implementations and use cases.
Count CSV
We implement a simple function that emits a Table data containing the number of objects detected in an image. This function inputs a Detection dataset and yields a Table dataset.
from skyhook.op import all_decorate
@all_decorate
def f(detections):
'''
Inputs (each input is a dict with keys 'Data' and 'Metadata'):
- detections: Data: Object detections: a list (or list of lists) of bounding boxes.
Each detection has keys Left, Top, Right, Bottom, and optionally Category, TrackID, Score, Metadata.
Metadata: Optional keys CanvasDims and Categories.
Example: {"Data": [{"Left": 100, "Right": 150, "Top": 300, "Bottom": 350}], "Metadata": {"CanvasDims": [1280, 720]}}
Returns: a tuple where elements are either data only or a dict with keys 'Data' and 'Metadata'
- Index 0 (table): Data: A list of list of strings, where each sub-list corresponds to the values in one row.
Metadata: A list of each columns, where each column is specified by a dict with keys Label, Type.
Example: {"Metadata": {"Columns": [{"Label": "Column 1", "Type": "string"}]}, "Data": [["Row 1"], ["Row 2"]]}
'''
count = 0
if detections['Data'] and detections['Data'][0]:
count = len(detections['Data'][0])
return {
'Metadata': {'Columns': [{'Label': 'count', 'Type': 'int'}, {'Label': 'blah', 'Type': 'orange'}]},
'Data': [[str(count), "orange"]],
}
Integer Label Splitter
Suppose that you have used the integer annotation tool to label two different things, like "13" means 1 of thing A and 3 for thing B. We can write a function to split the integer labels into integers for the two different things.
@lib.per_frame_decorate
def f(data):
'''
Inputs (each input is a dict with keys 'Data' and 'Metadata'):
- Data: A list of integers, or a single integer.
Metadata: Optional key Categories.
Example: {"Data": 2, "Metadata": {"Categories": ["person", "car", "giraffe"]}}
Returns: a tuple where elements are either data only or a dict with keys 'Data' and 'Metadata'
- Index 0 (left): Data: A list of integers, or a single integer.
Metadata: Optional key Categories.
Example: {"Data": 2, "Metadata": {"Categories": ["person", "car", "giraffe"]}}
- Index 1 (right): Data: A list of integers, or a single integer.
Metadata: Optional key Categories.
Example: {"Data": 2, "Metadata": {"Categories": ["person", "car", "giraffe"]}}
'''
x = data['Data']
left = x//10
right = x%10
return {'Data': left-1}, {'Data': right-1}